When you're training supervised machine learning models, you often hear about a loss function that is minimized; that must be chosen, and so on.
The term cost function is also used equivalently.
But what is loss? And what is a loss function?
I'll answer these two questions in this blog, which focuses on this optimization aspect of machine learning. We'll first cover the high-level supervised learning process, to set the stage. This includes the role of training, validation and testing data when training supervised models.
Once we're up to speed with those, we'll introduce loss. We answer the question what is loss? However, we don't forget what is a loss function? We'll even look into some commonly used loss functions.
Let's go! 😎
The high-level supervised learning process
Before we can actually introduce the concept of loss, we'll have to take a look at the high-level supervised machine learning process. All supervised training approaches fall under this process, which means that it is equal for deep neural networks such as MLPs or ConvNets, but also for SVMs.
Let's take a look at this training process, which is cyclical in nature.

Forward pass
We start with our features and targets, which are also called your dataset. This dataset is split into three parts before the training process starts: training data, validation data and testing data. The training data is used during the training process; more specificially, to generate predictions during the forward pass. However, after each training cycle, the predictive performance of the model must be tested. This is what the validation data is used for - it helps during model optimization.
Then there is testing data left. Assume that the validation data, which is essentially a statistical sample, does not fully match the population it describes in statistical terms. That is, the sample does not represent it fully and by consequence the mean and variance of the sample are (hopefully) slightly different than the actual population mean and variance. Hence, a little bias is introduced into the model every time you'll optimize it with your validation data. While it may thus still work very well in terms of predictive power, it may be the case that it will lose its power to generalize. In that case, it would no longer work for data it has never seen before, e.g. data from a different sample. The testing data is used to test the model once the entire training process has finished (i.e., only after the last cycle), and allows us to tell something about the generalization power of our machine learning model.
The training data is fed into the machine learning model in what is called the forward pass. The origin of this name is really easy: the data is simply fed to the network, which means that it passes through it in a forward fashion. The end result is a set of predictions, one per sample. This means that when my training set consists of 1000 feature vectors (or rows with features) that are accompanied by 1000 targets, I will have 1000 predictions after my forward pass.
Loss
You do however want to know how well the model performs with respect to the targets originally set. A well-performing model would be interesting for production usage, whereas an ill-performing model must be optimized before it can be actually used.
This is where the concept of loss enters the equation.
Most generally speaking, the loss allows us to compare between some actual targets and predicted targets. It does so by imposing a "cost" (or, using a different term, a "loss") on each prediction if it deviates from the actual targets.
It's relatively easy to compute the loss conceptually: we agree on some cost for our machine learning predictions, compare the 1000 targets with the 1000 predictions and compute the 1000 costs, then add everything together and present the global loss.
Our goal when training a machine learning model?
To minimize the loss.
The reason why is simple: the lower the loss, the more the set of targets and the set of predictions resemble each other.
And the more they resemble each other, the better the machine learning model performs.
As you can see in the machine learning process depicted above, arrows are flowing backwards towards the machine learning model. Their goal: to optimize the internals of your model only slightly, so that it will perform better during the next cycle (or iteration, or epoch, as they are also called).
Backwards pass
When loss is computed, the model must be improved. This is done by propagating the error backwards to the model structure, such as the model's weights. This closes the learning cycle between feeding data forward, generating predictions, and improving it - by adapting the weights, the model likely improves (sometimes much, sometimes slightly) and hence learning takes place.
Depending on the model type used, there are many ways for optimizing the model, i.e. propagating the error backwards. In neural networks, often, a combination of gradient descent based methods and backpropagation is used: gradient descent like optimizers for computing the gradient or the direction in which to optimize, backpropagation for the actual error propagation.
In other model types, such as Support Vector Machines, we do not actually propagate the error backward, strictly speaking. However, we use methods such as quadratic optimization to find the mathematical optimum, which given linear separability of your data (whether in regular space or kernel space) must exist. However, visualizing it as "adapting the weights by computing some error" benefits understanding. Next up - the loss functions we can actually use for computing the error! 😄
Loss functions
Here, we'll cover a wide array of loss functions: some of them for regression, others for classification.
Loss functions for regression
There are two main types of supervised learning problems: classification and regression. In the first, your aim is to classify a sample into the correct bucket, e.g. into one of the buckets 'diabetes' or 'no diabetes'. In the latter case, however, you don't classify but rather estimate some real valued number. What you're trying to do is regress a mathematical function from some input data, and hence it's called regression. For regression problems, there are many loss functions available.
Mean Absolute Error (L1 Loss)
Mean Absolute Error (MAE) is one of them. This is what it looks like:
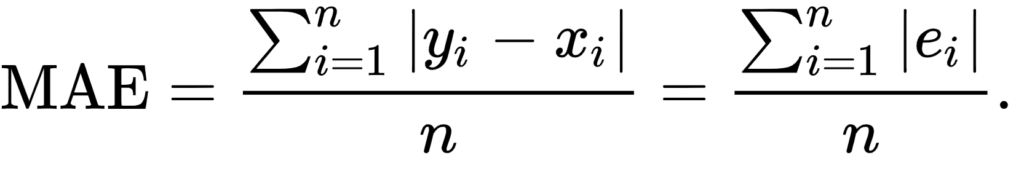
Don't worry about the maths, we'll introduce the MAE intuitively now.
That weird E-like sign you see in the formula is what is called a Sigma sign, and it sums up what's behind it: |Ei|, in our case, where Ei is the error (the difference between prediction and actual value) and the | signs mean that you're taking the absolute value, or convert -3 into 3 and 3 remains 3.
The summation, in this case, means that we sum all the errors, for all the n samples that were used for training the model. We therefore, after doing so, end up with a very large number. We divide this number by n, or the number of samples used, to find the mean, or the average Absolute Error: the Mean Absolute Error or MAE.
It's very well possible to use the MAE in a multitude of regression scenarios (Rich, n.d.). However, if your average error is very small, it may be better to use the Mean Squared Error that we will introduce next.
What's more, and this is important: when you use the MAE in optimizations that use gradient descent, you'll face the fact that the gradients are continuously large (Grover, 2019). Since this also occurs when the loss is low (and hence, you would only need to move a tiny bit), this is bad for learning - it's easy to overshoot the minimum continously, finding a suboptimal model. Consider Huber loss (more below) if you face this problem. If you face larger errors and don't care (yet?) about this issue with gradients, or if you're here to learn, let's move on to Mean Squared Error!
Mean Squared Error
Another loss function used often in regression is Mean Squared Error (MSE). It sounds really difficult, especially when you look at the formula (Binieli, 2018):
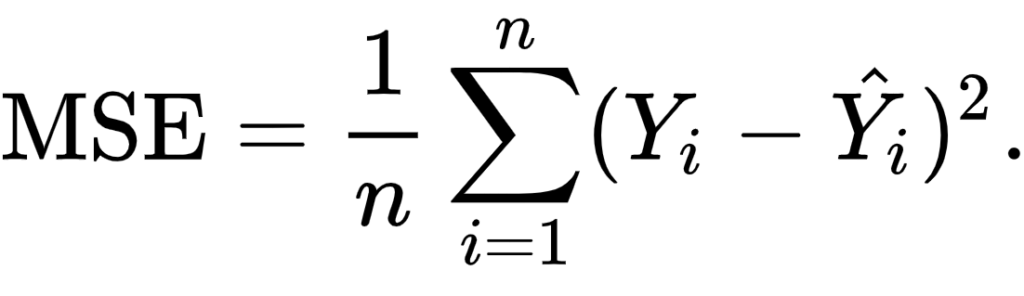
... but fear not. It's actually really easy to understand what MSE is and what it does!
We'll break the formula above into three parts, which allows us to understand each element and subsequently how they work together to produce the MSE.
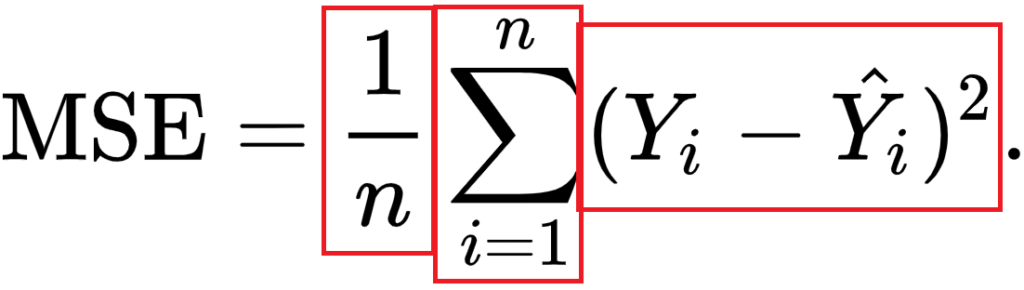
The primary part of the MSE is the middle part, being the Sigma symbol or the summation sign. What it does is really simple: it counts from i to n, and on every count executes what's written behind it. In this case, that's the third part - the square of (Yi - Y'i).
In our case, i starts at 1 and n is not yet defined. Rather, n is the number of samples in our training set and hence the number of predictions that has been made. In the scenario sketched above, n would be 1000.
Then, the third part. It's actually mathematical notation for what we already intuitively learnt earlier: it's the difference between the actual target for the sample (Yi) and the predicted target (Y'i), the latter of which is removed from the first.
With one minor difference: the end result of this computation is squared. This property introduces some mathematical benefits during optimization (Rich, n.d.). Particularly, the MSE is continuously differentiable whereas the MAE is not (at x = 0). This means that optimizing the MSE is easier than optimizing the MAE.
Additionally, large errors introduce a much larger cost than smaller errors (because the differences are squared and larger errors produce much larger squares than smaller errors). This is both good and bad at the same time (Rich, n.d.). This is a good property when your errors are small, because optimization is then advanced (Quora, n.d.). However, using MSE rather than e.g. MAE will open your ML model up to outliers, which will severely disturb training (by means of introducing large errors).
Although the conclusion may be rather unsatisfactory, choosing between MAE and MSE is thus often heavily dependent on the dataset you're using, introducing the need for some a priori inspection before starting your training process.
Finally, when we have the sum of the squared errors, we divide it by n - producing the mean squared error.
Mean Absolute Percentage Error
The Mean Absolute Percentage Error, or MAPE, really looks like the MAE, even though the formula looks somewhat different:

When using the MAPE, we don't compute the absolute error, but rather, the mean error percentage with respect to the actual values. That is, suppose that my prediction is 12 while the actual target is 10, the MAPE for this prediction is \(| (10 - 12 ) / 10 | = 0.2\).
Similar to the MAE, we sum the error over all the samples, but subsequently face a different computation: \(100\% / n\). This looks difficult, but we can once again separate this computation into more easily understandable parts. More specifically, we can write it as a multiplication of \(100\%\) and \(1 / n\) instead. When multiplying the latter with the sum, you'll find the same result as dividing it by n, which we did with the MAE. That's great.
The only thing left now is multiplying the whole with 100%. Why do we do that? Simple: because our computed error is a ratio and not a percentage. Like the example above, in which our error was 0.2, we don't want to find the ratio, but the percentage instead. \(0.2 \times 100\%\) is ... unsurprisingly ... \(20\%\)! Hence, we multiply the mean ratio error with the percentage to find the MAPE! :-)
Why use MAPE if you can also use MAE?
Very good question.
Firstly, it is a very intuitive value. Contrary to the absolute error, we have a sense of how well-performing the model is or how bad it performs when we can express the error in terms of a percentage. An error of 100 may seem large, but if the actual target is 1000000 while the estimate is 1000100, well, you get the point.
Secondly, it allows us to compare the performance of regression models on different datasets (Watson, 2019). Suppose that our goal is to train a regression model on the NASDAQ ETF and the Dutch AEX ETF. Since their absolute values are quite different, using MAE won't help us much in comparing the performance of our model. MAPE, on the other hand, demonstrates the error in terms of a percentage - and a percentage is a percentage, whether you apply it to NASDAQ or to AEX. This way, it's possible to compare model performance across statistically varying datasets.
Root Mean Squared Error (L2 Loss)
Remember the MSE?
There's also something called the RMSE, or the Root Mean Squared Error or Root Mean Squared Deviation (RMSD). It goes like this:
Simple, hey? It's just the MSE but then its square root value.
How does this help us?
The errors of the MSE are squared - hey, what's in a name.
The RMSE or RMSD errors are root squares of the square - and hence are back at the scale of the original targets (Dragos, 2018). This gives you much better intuition for the error in terms of the targets.
Logcosh
"Log-cosh is the logarithm of the hyperbolic cosine of the prediction error." (Grover, 2019).
Well, how's that for a starter.
This is the mathematical formula:
And this the plot:

Okay, now let's introduce some intuitive explanation.
The TensorFlow docs write this about Logcosh loss:
log(cosh(x))is approximately equal to(x ** 2) / 2for smallxand toabs(x) - log(2)for largex. This means that 'logcosh' works mostly like the mean squared error, but will not be so strongly affected by the occasional wildly incorrect prediction.
Well, that's great. It seems to be an improvement over MSE, or L2 loss. Recall that MSE is an improvement over MAE (L1 Loss) if your data set contains quite large errors, as it captures these better. However, this also means that it is much more sensitive to errors than the MAE. Logcosh helps against this problem:
- For relatively small errors (even with the relatively small but larger errors, which is why MSE can be better for your ML problem than MAE) it outputs approximately equal to \(x^2 / 2\) - which is pretty equal to the \(x^2\) output of the MSE.
- For larger errors, i.e. outliers, where MSE would produce extremely large errors (\((10^6)^2 = 10^12\)), the Logcosh approaches \(|x| - log(2)\). It's like (as well as unlike) the MAE, but then somewhat corrected by the
log.
Hence: indeed, if you have both larger errors that must be detected as well as outliers, which you perhaps cannot remove from your dataset, consider using Logcosh! It's available in many frameworks like TensorFlow as we saw above, but also in Keras.
Huber loss
Let's move on to Huber loss, which we already hinted about in the section about the MAE:
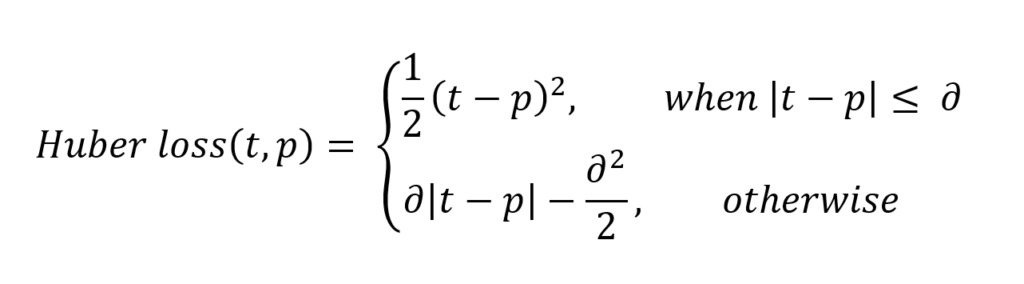
Or, visually:

When interpreting the formula, we see two parts:
- \(1/2 \times (t-p)^2\), when \(|t-p| \leq \delta\). This sounds very complicated, but we can break it into parts easily.
- \(|t-p|\) is the absolute error: the difference between target \(t\) and prediction \(p\).
- We square it and divide it by two.
- We however only do so when the absolute error is smaller than or equal to some \(\delta\), also called delta, which you can configure! We'll see next why this is nice.
- When the absolute error is larger than \(\delta\), we compute the error as follows: \(\delta \times |t-p| - (\delta^2 / 2)\).
- Let's break this apart again. We multiply the delta with the absolute error and remove half of delta square.
What is the effect of all this mathematical juggling?
Look at the visualization above.
For relatively small deltas (in our case, with \(\delta = 0.25\), you'll see that the loss function becomes relatively flat. It takes quite a long time before loss increases, even when predictions are getting larger and larger.
For larger deltas, the slope of the function increases. As you can see, the larger the delta, the slower the increase of this slope: eventually, for really large \(\delta\) the slope of the loss tends to converge to some maximum.
If you look closely, you'll notice the following:
- With small \(\delta\), the loss becomes relatively insensitive to larger errors and outliers. This might be good if you have them, but bad if on average your errors are small.
- With large \(\delta\), the loss becomes increasingly sensitive to larger errors and outliers. That might be good if your errors are small, but you'll face trouble when your dataset contains outliers.
Hey, haven't we seen that before?
Yep: in our discussions about the MAE (insensitivity to larger errors) and the MSE (fixes this, but facing sensitivity to outliers).
Grover (2019) writes about this nicely:
Huber loss approaches MAE when 𝛿 ~ 0 and MSE when 𝛿 ~ ∞ (large numbers.)
That's what this \(\delta\) is for! You are now in control about the 'degree' of MAE vs MSE-ness you'll introduce in your loss function. When you face large errors due to outliers, you can try again with a lower \(\delta\); if your errors are too small to be picked up by your Huber loss, you can increase the delta instead.
And there's another thing, which we also mentioned when discussing the MAE: it produces large gradients when you optimize your model by means of gradient descent, even when your errors are small (Grover, 2019). This is bad for model performance, as you will likely overshoot the mathematical optimum for your model. You don't face this problem with MSE, as it tends to decrease towards the actual minimum (Grover, 2019). If you switch to Huber loss from MAE, you might find it to be an additional benefit.
Here's why: Huber loss, like MSE, decreases as well when it approaches the mathematical optimum (Grover, 2019). This means that you can combine the best of both worlds: the insensitivity to larger errors from MAE with the sensitivity of the MSE and its suitability for gradient descent. Hooray for Huber loss! And like always, it's also available when you train models with Keras.
Then why isn't this the perfect loss function?
Because the benefit of the \(\delta\) is also becoming your bottleneck (Grover, 2019). As you have to configure them manually (or perhaps using some automated tooling), you'll have to spend time and resources on finding the most optimum \(\delta\) for your dataset. This is an iterative problem that, in the extreme case, may become impractical at best and costly at worst. However, in most cases, it's best just to experiment - perhaps, you'll find better results!
Loss functions for classification
Loss functions are also applied in classifiers. I already discussed in another post what classification is all about, so I'm going to repeat it here:
Suppose that you work in the field of separating non-ripe tomatoes from the ripe ones. It’s an important job, one can argue, because we don’t want to sell customers tomatoes they can’t process into dinner. It’s the perfect job to illustrate what a human classifier would do.
Humans have a perfect eye to spot tomatoes that are not ripe or that have any other defect, such as being rotten. They derive certain characteristics for those tomatoes, e.g. based on color, smell and shape:
- If it’s green, it’s likely to be unripe (or: not sellable);
- If it smells, it is likely to be unsellable;
- The same goes for when it’s white or when fungus is visible on top of it.If none of those occur, it’s likely that the tomato can be sold. We now have two classes: sellable tomatoes and non-sellable tomatoes. Human classifiers decide about which class an object (a tomato) belongs to.
The same principle occurs again in machine learning and deep learning.
Only then, we replace the human with a machine learning model. We’re then using machine learning for classification, or for deciding about some “model input” to “which class” it belongs.
We'll now cover loss functions that are used for classification.
Hinge
The hinge loss is defined as follows (Wikipedia, 2011):
It simply takes the maximum of either 0 or the computation \( 1 - t \times y\), where t is the machine learning output value (being between -1 and +1) and y is the true target (-1 or +1).
When the target equals the prediction, the computation \(t \times y\) is always one: \(1 \times 1 = -1 \times -1 = 1)\). Essentially, because then \(1 - t \times y = 1 - 1 = 1\), the max function takes the maximum \(max(0, 0)\), which of course is 0.
That is: when the actual target meets the prediction, the loss is zero. Negative loss doesn't exist. When the target != the prediction, the loss value increases.
For t = 1, or \(1\) is your target, hinge loss looks like this:

Let's now consider three scenarios which can occur, given our target \(t = 1\) (Kompella, 2017; Wikipedia, 2011):
- The prediction is correct, which occurs when \(y \geq 1.0\).
- The prediction is very incorrect, which occurs when \(y < 0.0\) (because the sign swaps, in our case from positive to negative).
- The prediction is not correct, but we're getting there (\( 0.0 \leq y < 1.0\)).
In the first case, e.g. when \(y = 1.2\), the output of \(1 - t \ times y\) will be \( 1 - ( 1 \times 1.2 ) = 1 - 1.2 = -0.2\). Loss, then will be \(max(0, -0.2) = 0\). Hence, for all correct predictions - even if they are too correct, loss is zero. In the too correct situation, the classifier is simply very sure that the prediction is correct (Peltarion, n.d.).
In the second case, e.g. when \(y = -0.5\), the output of the loss equation will be \(1 - (1 \ times -0.5) = 1 - (-0.5) = 1.5\), and hence the loss will be \(max(0, 1.5) = 1.5\). Very wrong predictions are hence penalized significantly by the hinge loss function.
In the third case, e.g. when \(y = 0.9\), loss output function will be \(1 - (1 \times 0.9) = 1 - 0.9 = 0.1\). Loss will be \(max(0, 0.1) = 0.1\). We're getting there - and that's also indicated by the small but nonzero loss.
What this essentially sketches is a margin that you try to maximize: when the prediction is correct or even too correct, it doesn't matter much, but when it's not, we're trying to correct. The correction process keeps going until the prediction is fully correct (or when the human tells the improvement to stop). We're thus finding the most optimum decision boundary and are hence performing a maximum-margin operation.
It is therefore not surprising that hinge loss is one of the most commonly used loss functions in Support Vector Machines (Kompella, 2017). What's more, hinge loss itself cannot be used with gradient descent like optimizers, those with which (deep) neural networks are trained. This occurs due to the fact that it's not continuously differentiable, more precisely at the 'boundary' between no loss / minimum loss. Fortunately, a subgradient of the hinge loss function can be optimized, so it can (albeit in a different form) still be used in today's deep learning models (Wikipedia, 2011). For example, hinge loss is available as a loss function in Keras.
Squared hinge
The squared hinge loss is like the hinge formula displayed above, but then the \(max()\) function output is squared.
This helps achieving two things:
- Firstly, it makes the loss value more sensitive to outliers, just as we saw with MSE vs MAE. Large errors will add to the loss more significantly than smaller errors. Note that simiarly, this may also mean that you'll need to inspect your dataset for the presence of such outliers first.
- Secondly, squared hinge loss is differentiable whereas hinge loss is not (Tay, n.d.). The way the hinge loss is defined makes it not differentiable at the 'boundary' point of the chart - also see this perfect answer that illustrates it. Squared hinge loss, on the other hand, is differentiable, simply because of the square and the mathematical benefits it introduces during differentiation. This makes it easier for us to use a hinge-like loss in gradient based optimization - we'll simply take squared hinge.
Categorical / multiclass hinge
Both normal hinge and squared hinge loss work only for binary classification problems in which the actual target value is either +1 or -1. Although that's perfectly fine for when you have such problems (e.g. the diabetes yes/no problem that we looked at previously), there are many other problems which cannot be solved in a binary fashion.
(Note that one approach to create a multiclass classifier, especially with SVMs, is to create many binary ones, feeding the data to each of them and counting classes, eventually taking the most-chosen class as output - it goes without saying that this is not very efficient.)
However, in neural networks and hence gradient based optimization problems, we're not interested in doing that. It would mean that we have to train many networks, which significantly impacts the time performance of our ML training problem. Instead, we can use the multiclass hinge that has been introduced by researchers Weston and Watkins (Wikipedia, 2011):
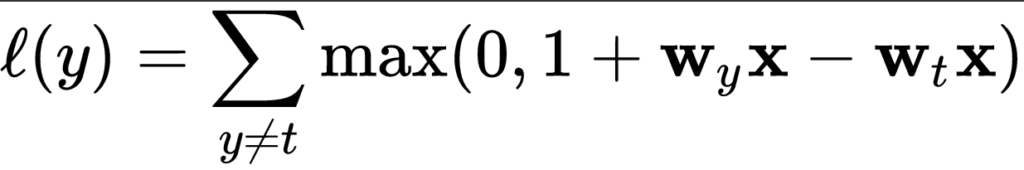
What this means in plain English is this:
For all \(y\) (output) values unequal to \(t\), compute the loss. Eventually, sum them together to find the multiclass hinge loss.
Note that this does not mean that you sum over all possible values for y (which would be all real-valued numbers except \(t\)), but instead, you compute the sum over all the outputs generated by your ML model during the forward pass. That is, all the predictions. Only for those where \(y \neq t\), you compute the loss. This is obvious from an efficiency point of view: where \(y = t\), loss is always zero, so no \(max\) operation needs to be computed to find zero after all.
Keras implements the multiclass hinge loss as categorical hinge loss, requiring to change your targets into categorical format (one-hot encoded format) first by means of to_categorical.
Binary crossentropy
A loss function that's used quite often in today's neural networks is binary crossentropy. As you can guess, it's a loss function for binary classification problems, i.e. where there exist two classes. Primarily, it can be used where the output of the neural network is somewhere between 0 and 1, e.g. by means of the Sigmoid layer.
This is its formula:
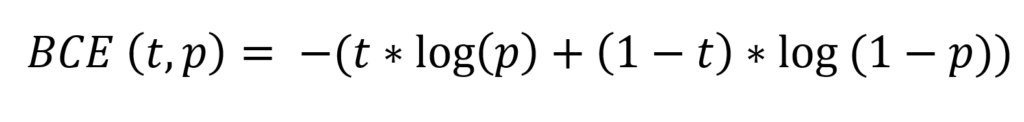
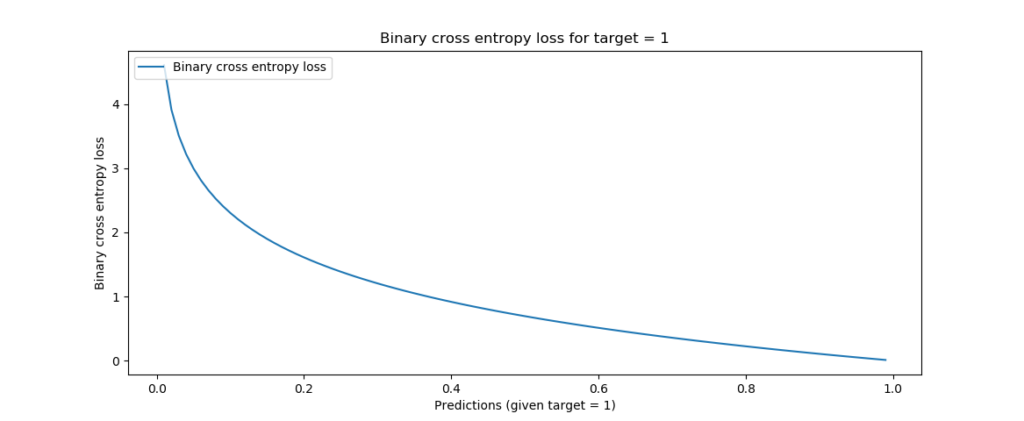
It can be visualized in this way:
And, like before, let's now explain it in more intuitive ways.
The \(t\) in the formula is the target (0 or 1) and the \(p\) is the prediction (a real-valued number between 0 and 1, for example 0.12326).
When you input both into the formula, loss will be computed related to the target and the prediction. In the visualization above, where the target is 1, it becomes clear that loss is 0. However, when moving to the left, loss tends to increase (ML Cheatsheet documentation, n.d.). What's more, it increases increasingly fast. Hence, it not only tends to punish wrong predictions, but also wrong predictions that are extremely confident (i.e., if the model is very confident that it's 0 while it's 1, it gets punished much harder than when it thinks it's somewhere in between, e.g. 0.5). This latter property makes the binary cross entropy a valued loss function in classification problems.
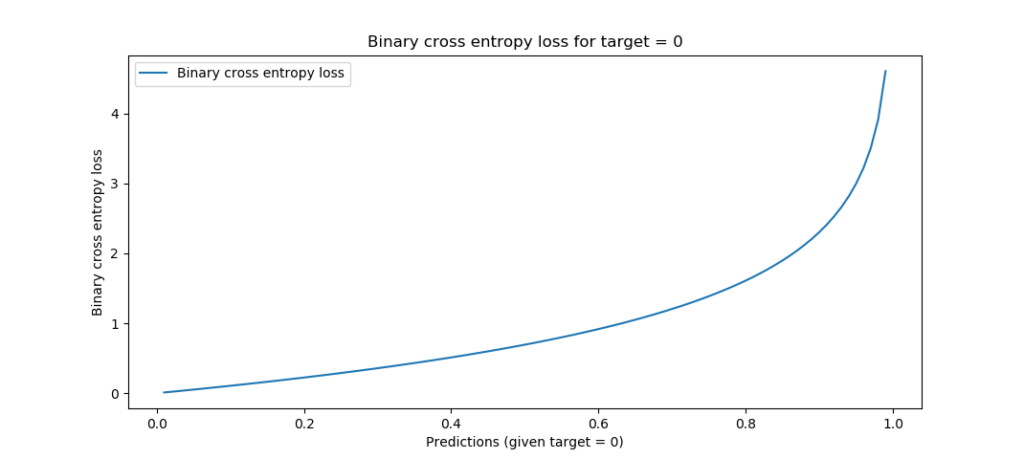
When the target is 0, you can see that the loss is mirrored - which is exactly what we want:
Categorical crossentropy
Now what if you have no binary classification problem, but instead a multiclass one?
Thus: one where your output can belong to one of > 2 classes.
The CNN that we created with Keras using the MNIST dataset is a good example of this problem. As you can find in the blog (see the link), we used a different loss function there - categorical crossentropy. It's still crossentropy, but then adapted to multiclass problems.
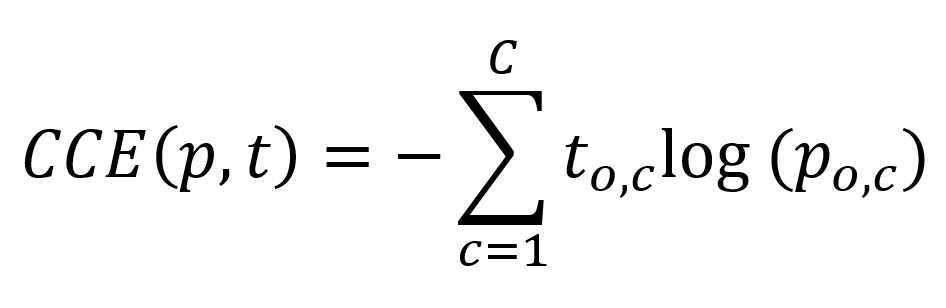
This is the formula with which we compute categorical crossentropy. Put very simply, we sum over all the classes that we have in our system, compute the target of the observation and the prediction of the observation and compute the observation target with the natural log of the observation prediction.
It took me some time to understand what was meant with a prediction, though, but thanks to Peltarion (n.d.), I got it.
The answer lies in the fact that the crossentropy is categorical and that hence categorical data is used, with one-hot encoding.
Suppose that we have dataset that presents what the odds are of getting diabetes after five years, just like the Pima Indians dataset we used before. However, this time another class is added, being "Possibly diabetic", rendering us three classes for one's condition after five years given current measurements:
- 0: no diabetes
- 1: possibly diabetic
- 2: diabetic
That dataset would look like this:
| Features | Target |
| { … } | 1 |
| { … } | 2 |
| { … } | 0 |
| { … } | 0 |
| { … } | 2 |
| …and so on | …and so on |
However, categorical crossentropy cannot simply use integers as targets, because its formula doesn't support this. Instead, we must apply one-hot encoding, which transforms the integer targets into categorial vectors, which are just vectors that displays all categories and whether it's some class or not:
- 0: \([1, 0, 0]\)
- 1: \([0, 1, 0]\)
- 2: \([0, 0, 1]\)
That's what we always do with to_categorical in Keras.
Our dataset then looks as follows:
| Features | Target |
| { … } | [latex][0, 1, 0][/latex] |
| { … } | [latex][0, 0, 1][/latex] |
| { … } | [latex][1, 0, 0][/latex] |
| { … } | [latex][1, 0, 0][/latex] |
| { … } | [latex][0, 0, 1][/latex] |
| …and so on | …and so on |
Now, we can explain with is meant with an observation.
Let's look at the formula again and recall that we iterate over all the possible output classes - once for every prediction made, with some true target:
Now suppose that our trained model outputs for the set of features \({ ... }\) or a very similar one that has target \([0, 1, 0]\) a probability distribution of \([0.25, 0.50, 0.25]\) - that's what these models do, they pick no class, but instead compute the probability that it's a particular class in the categorical vector.
Computing the loss, for \(c = 1\), what is the target value? It's 0: in \(\textbf{t} = [0, 1, 0]\), the target value for class 0 is 0.
What is the prediction? Well, following the same logic, the prediction is 0.25.
We call these two observations with respect to the total prediction. By looking at all observations, merging them together, we can find the loss value for the entire prediction.
We multiply the target value with the log. But wait! We multiply the log with 0 - so the loss value for this target is 0.
It doesn't surprise you that this happens for all targets except for one - where the target value is 1: in the prediction above, that would be for the second one.
Note that when the sum is complete, you'll multiply it with -1 to find the true categorical crossentropy loss.
Hence, loss is driven by the actual target observation of your sample instead of all the non-targets. The structure of the formula however allows us to perform multiclass machine learning training with crossentropy. There we go, we learnt another loss function :-)
Sparse categorical crossentropy
But what if we don't want to convert our integer targets into categorical format? We can use sparse categorical crossentropy instead (Lin, 2019).
It performs in pretty much similar ways to regular categorical crossentropy loss, but instead allows you to use integer targets! That's nice.
| Features | Target |
| { … } | 1 |
| { … } | 2 |
| { … } | 0 |
| { … } | 0 |
| { … } | 2 |
| …and so on | …and so on |
Kullback-Leibler divergence
Sometimes, machine learning problems involve the comparison between two probability distributions. An example comparison is the situation below, in which the question is how much the uniform distribution differs from the Binomial(10, 0.2) distribution.

When you wish to compare two probability distributions, you can use the Kullback-Leibler divergence, a.k.a. KL divergence (Wikipedia, 2004):
\begin{equation} KL (P || Q) = \sum p(X) \log ( p(X) \div q(X) ) \end{equation}
KL divergence is an adaptation of entropy, which is a common metric in the field of information theory (Wikipedia, 2004; Wikipedia, 2001; Count Bayesie, 2017). While intuitively, entropy tells you something about "the quantity of your information", KL divergence tells you something about "the change of quantity when distributions are changed".
Your goal in machine learning problems is to ensure that \(change \approx 0\).
Is KL divergence used in practice? Yes! Generative machine learning models work by drawing a sample from encoded, latent space, which effectively represents a latent probability distribution. In other scenarios, you might wish to perform multiclass classification with neural networks that use Softmax activation in their output layer, effectively generating a probability distribution across the classes. And so on. In those cases, you can use KL divergence loss during training. It compares the probability distribution represented by your training data with the probability distribution generated during your forward pass, and computes the divergence (the difference, although when you swap distributions, the value changes due to non-symmetry of KL divergence - hence it's not entirely the difference) between the two probability distributions. This is your loss value. Minimizing the loss value thus essentially steers your neural network towards the probability distribution represented in your training set, which is what you want.
Summary
In this blog, we've looked at the concept of loss functions, also known as cost functions. We showed why they are necessary by means of illustrating the high-level machine learning process and (at a high level) what happens during optimization. Additionally, we covered a wide range of loss functions, some of them for classification, others for regression. Although we introduced some maths, we also tried to explain them intuitively.
I hope you've learnt something from my blog! If you have any questions, remarks, comments or other forms of feedback, please feel free to leave a comment below! 👇 I'd also appreciate a comment telling me if you learnt something and if so, what you learnt. I'll gladly improve my blog if mistakes are made. Thanks and happy engineering! 😎
References
Chollet, F. (2017). Deep Learning with Python. New York, NY: Manning Publications.
Keras. (n.d.). Losses. Retrieved from https://keras.io/losses/
Binieli, M. (2018, October 8). Machine learning: an introduction to mean squared error and regression lines. Retrieved from https://www.freecodecamp.org/news/machine-learning-mean-squared-error-regression-line-c7dde9a26b93/
Rich. (n.d.). Why square the difference instead of taking the absolute value in standard deviation? Retrieved from https://stats.stackexchange.com/a/121
Quora. (n.d.). What is the difference between squared error and absolute error? Retrieved from https://www.quora.com/What-is-the-difference-between-squared-error-and-absolute-error
Watson, N. (2019, June 14). Using Mean Absolute Error to Forecast Accuracy. Retrieved from https://canworksmart.com/using-mean-absolute-error-forecast-accuracy/
Drakos, G. (2018, December 5). How to select the Right Evaluation Metric for Machine Learning Models: Part 1 Regression Metrics. Retrieved from https://towardsdatascience.com/how-to-select-the-right-evaluation-metric-for-machine-learning-models-part-1-regrression-metrics-3606e25beae0
Wikipedia. (2011, September 16). Hinge loss. Retrieved from https://en.wikipedia.org/wiki/Hinge_loss
Kompella, R. (2017, October 19). Support vector machines ( intuitive understanding ) ? Part#1. Retrieved from https://towardsdatascience.com/support-vector-machines-intuitive-understanding-part-1-3fb049df4ba1
Peltarion. (n.d.). Squared hinge. Retrieved from https://peltarion.com/knowledge-center/documentation/modeling-view/build-an-ai-model/loss-functions/squared-hinge
Tay, J. (n.d.). Why is squared hinge loss differentiable? Retrieved from https://www.quora.com/Why-is-squared-hinge-loss-differentiable
Rakhlin, A. (n.d.). Online Methods in Machine Learning. Retrieved from http://www.mit.edu/~rakhlin/6.883/lectures/lecture05.pdf
Grover, P. (2019, September 25). 5 Regression Loss Functions All Machine Learners Should Know. Retrieved from https://heartbeat.fritz.ai/5-regression-loss-functions-all-machine-learners-should-know-4fb140e9d4b0
TensorFlow. (n.d.). tf.keras.losses.logcosh. Retrieved from https://www.tensorflow.org/api_docs/python/tf/keras/losses/logcosh
ML Cheatsheet documentation. (n.d.). Loss Functions. Retrieved from https://ml-cheatsheet.readthedocs.io/en/latest/loss_functions.html
Peltarion. (n.d.). Categorical crossentropy. Retrieved from https://peltarion.com/knowledge-center/documentation/modeling-view/build-an-ai-model/loss-functions/categorical-crossentropy
Lin, J. (2019, September 17). categorical_crossentropy VS. sparse_categorical_crossentropy. Retrieved from https://jovianlin.io/cat-crossentropy-vs-sparse-cat-crossentropy/
Wikipedia. (2004, February 13). Kullback–Leibler divergence. Retrieved from https://en.wikipedia.org/wiki/Kullback%E2%80%93Leibler_divergence
Wikipedia. (2001, July 9). Entropy (information theory). Retrieved from https://en.wikipedia.org/wiki/Entropy_(information_theory)
Count Bayesie. (2017, May 10). Kullback-Leibler Divergence Explained. Retrieved from https://www.countbayesie.com/blog/2017/5/9/kullback-leibler-divergence-explained

Hi, I'm Chris!
I know a thing or two about AI and machine learning. Welcome to MachineCurve.com, where machine learning is explained in gentle terms.
Getting started
Foundation models
Learn how large language models and other foundation models are working and how you can train open source ones yourself.
Keras
Keras is a high-level API for TensorFlow. It is one of the most popular deep learning frameworks.
Machine learning theory
Read about the fundamentals of machine learning, deep learning and artificial intelligence.
Most recent articles
January 2, 2024
What is Retrieval-Augmented Generation?
December 27, 2023
In-Context Learning: what it is and how it works
December 22, 2023
CLIP: how it works, how it's trained and how to use it
Article tags
Most popular articles
February 18, 2020
How to use K-fold Cross Validation with TensorFlow 2 and Keras?
December 28, 2020
Introduction to Transformers in Machine Learning
December 27, 2021
StyleGAN, a step-by-step introduction
July 17, 2019
This Person Does Not Exist - how does it work?
October 26, 2020
Your First Machine Learning Project with TensorFlow 2.0 and Keras
Connect on social media
Connect with me on LinkedIn
To get in touch with me, please connect with me on LinkedIn. Make sure to write me a message saying hi!
Side info
The content on this website is written for educational purposes. In writing the articles, I have attempted to be as correct and precise as possible. Should you find any errors, please let me know by creating an issue or pull request in this GitHub repository.
All text on this website written by me is copyrighted and may not be used without prior permission. Creating citations using content from this website is allowed if a reference is added, including an URL reference to the referenced article.
If you have any questions or remarks, feel free to get in touch.
TensorFlow, the TensorFlow logo and any related marks are trademarks of Google Inc.
PyTorch, the PyTorch logo and any related marks are trademarks of The Linux Foundation.
Montserrat and Source Sans are fonts licensed under the SIL Open Font License version 1.1.
Mathjax is licensed under the Apache License, Version 2.0.